
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 테슬라
- 아이온큐
- java crawler
- vavr
- 양자컴퓨터
- IONQ
- aqqle
- KNN
- aggs
- API
- request cache
- java
- ann
- Analyzer
- Aggregation
- file download
- elasticsearch cache
- Elastic
- api cache
- Elasticsearch
- TSLA
- redis
- mysql
- Selenium
- Cache
- NORI
- JPA
- Docker
- dbeaver
- Query
- Today
- Total
아빠는 개발자
[es] elasticsearch cache 모니터링 (query_cache, request_cache) 본문
[es] elasticsearch cache 모니터링 (query_cache, request_cache)
father6019 2023. 9. 24. 17:10검색 결과 리스팅은 Query Cache에, 검색 결과에 대한 집계 는 Request Cache 에 저장 된다
그렇다면 둘다 확인해서 multi_match + aggs 의 결과가 어디에 캐싱된건지 확인
GET /location-index/_stats/query_cache?human
{
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_all": {
"primaries": {
"query_cache": {
"memory_size": "0b",
"memory_size_in_bytes": 0,
"total_count": 0,
"hit_count": 0,
"miss_count": 0,
"cache_size": 0,
"cache_count": 0,
"evictions": 0
}
},
"total": {
"query_cache": {
"memory_size": "0b",
"memory_size_in_bytes": 0,
"total_count": 0,
"hit_count": 0,
"miss_count": 0,
"cache_size": 0,
"cache_count": 0,
"evictions": 0
}
}
},
"indices": {
"location-index": {
"uuid": "zA8IsMKdRjyjGK4KtIUXsg",
"health": "green",
"status": "open",
"primaries": {
"query_cache": {
"memory_size": "0b",
"memory_size_in_bytes": 0,
"total_count": 0,
"hit_count": 0,
"miss_count": 0,
"cache_size": 0,
"cache_count": 0,
"evictions": 0
}
},
"total": {
"query_cache": {
"memory_size": "0b",
"memory_size_in_bytes": 0,
"total_count": 0,
"hit_count": 0,
"miss_count": 0,
"cache_size": 0,
"cache_count": 0,
"evictions": 0
}
}
}
}
}
GET /_nodes/stats/indices/request_cache?human
{
"_nodes": {
"total": 1,
"successful": 1,
"failed": 0
},
"cluster_name": "docker-cluster",
"nodes": {
"bpumm1NjRAiDyuAgBN6XpQ": {
"timestamp": 1695543724849,
"name": "ee861c7e21e4",
"transport_address": "172.18.0.2:9300",
"host": "172.18.0.2",
"ip": "172.18.0.2:9300",
"roles": [
"data",
"data_cold",
"data_content",
"data_frozen",
"data_hot",
"data_warm",
"ingest",
"master",
"ml",
"remote_cluster_client",
"transform"
],
"attributes": {
"ml.machine_memory": "2081312768",
"xpack.installed": "true",
"ml.allocated_processors_double": "8.0",
"ml.max_jvm_size": "536870912",
"ml.allocated_processors": "8"
},
"indices": {
"request_cache": {
"memory_size": "22.1kb",
"memory_size_in_bytes": 22720,
"evictions": 0,
"hit_count": 0,
"miss_count": 59
}
}
}
}
}Monitoring Cache
Index별 Cache 통계
# GET /_stats/request_cache,query_cache?human
Node별 Cache 통계
# GET /_nodes/stats/indices/request_cache,query_cache?human
특정 Index의 Cache 통계
# GET index_name/_stats/request_cache,query_cache?human
Clear cache
특정 Index의 Cache 삭제
# POST /my-index-000001/_cache/clear
# POST /my-index-000001,my-index-000002/_cache/clear
모든 Index의 Cache 삭제
# POST /_cache/clear
특정 Index의 특정 Cache 삭제
# POST /my-index-000001/_cache/clear?fielddata=true
# POST /my-index-000001/_cache/clear?query=true
# POST /my-index-000001/_cache/clear?request=true
특정 Index의 특정 field의 Cache 삭제
# POST /my-index-000001/_cache/clear?fields=foo,bar
이런식으로 닝겐이 알아보기 쉽게? 표시해주는데 테스트해보자
캐시삭제
POST /<target>/_cache/clear
POST /_cache/clear
case 1.
케시 지우고
multi_match + aggs 2개 필드 조회 X 300 키워드
query
{
"query": {
"multi_match" : {
"query": "{keyword}",
"fields": [ "country_code"]
}
},
"aggs": {
"CITY": {
"terms": {
"field": "city"
}
},
"COUNTRY": {
"terms": {
"field": "country"
}
}
}
}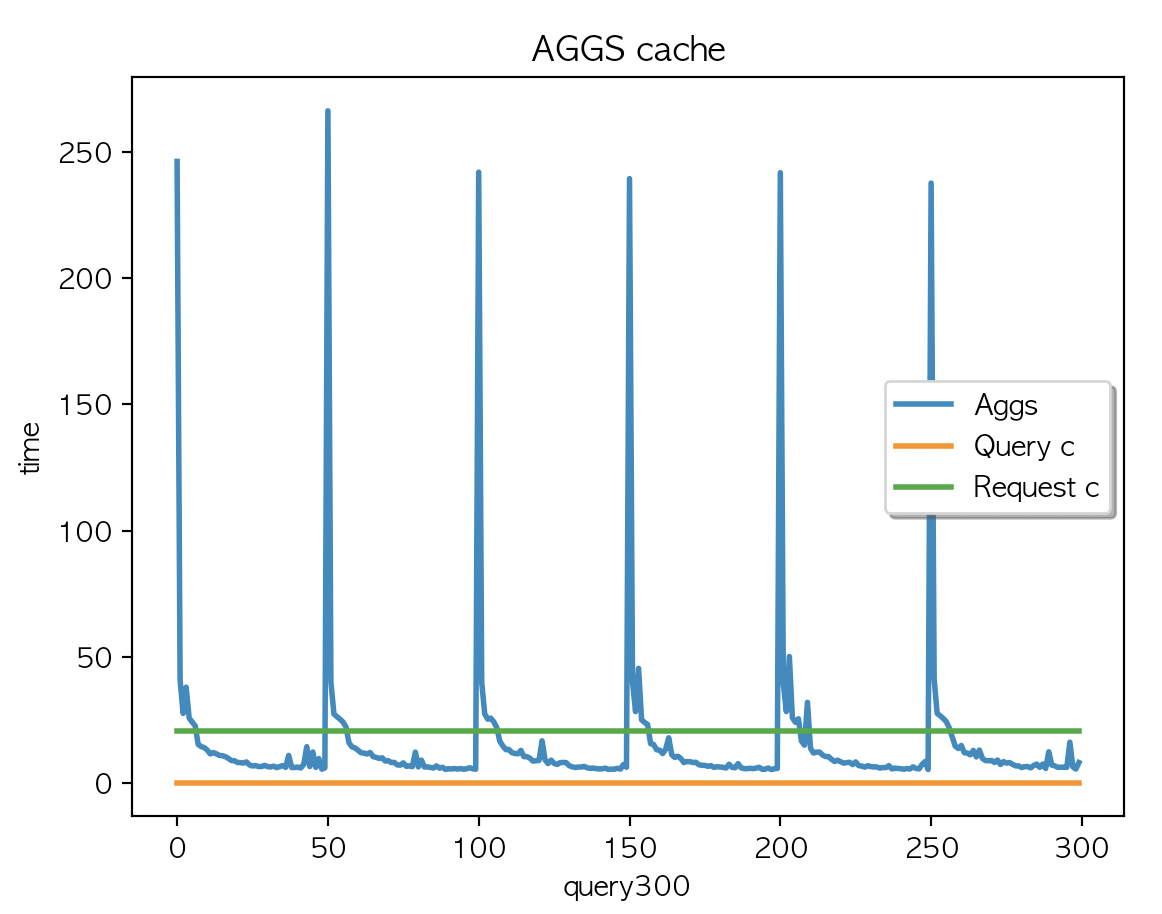 |
 |
 |
| AGGS 평균 : 15.69 | AGGS 평균 : 15.63 | AGGS 평균 : 15.42 |
캐싱은 되지 않았고 (캐시 사이즈 변경 없음) Aggs 속도는 50개 키워드 X 6회 반복 이였는데 첫 쿼리에서 저런 모양이.
Case 2.
케시 지우고
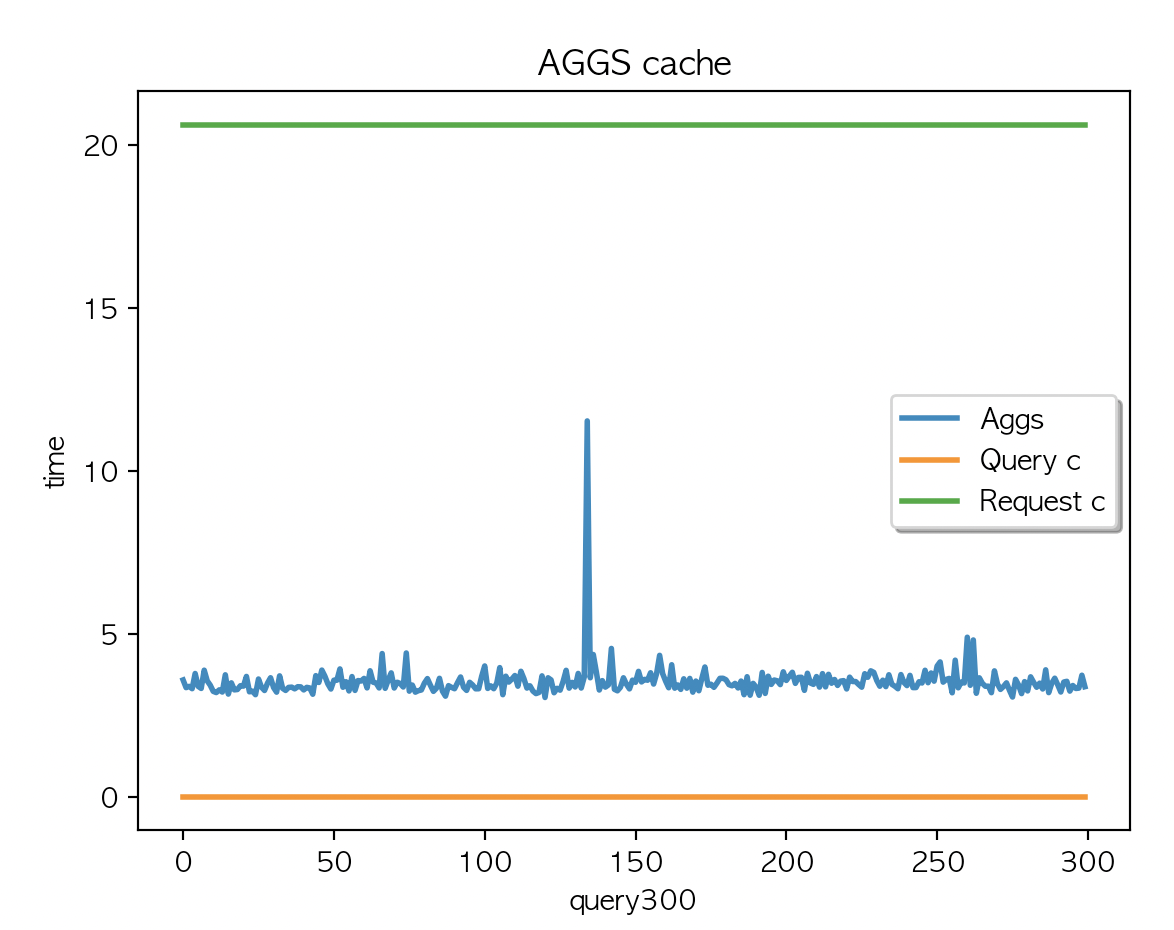
multi_match 쿼리만 X 300 키워드 실행
{
"query": {
"multi_match": {
"query": "{keyword}",
"fields": [
"country_code"
]
}
}
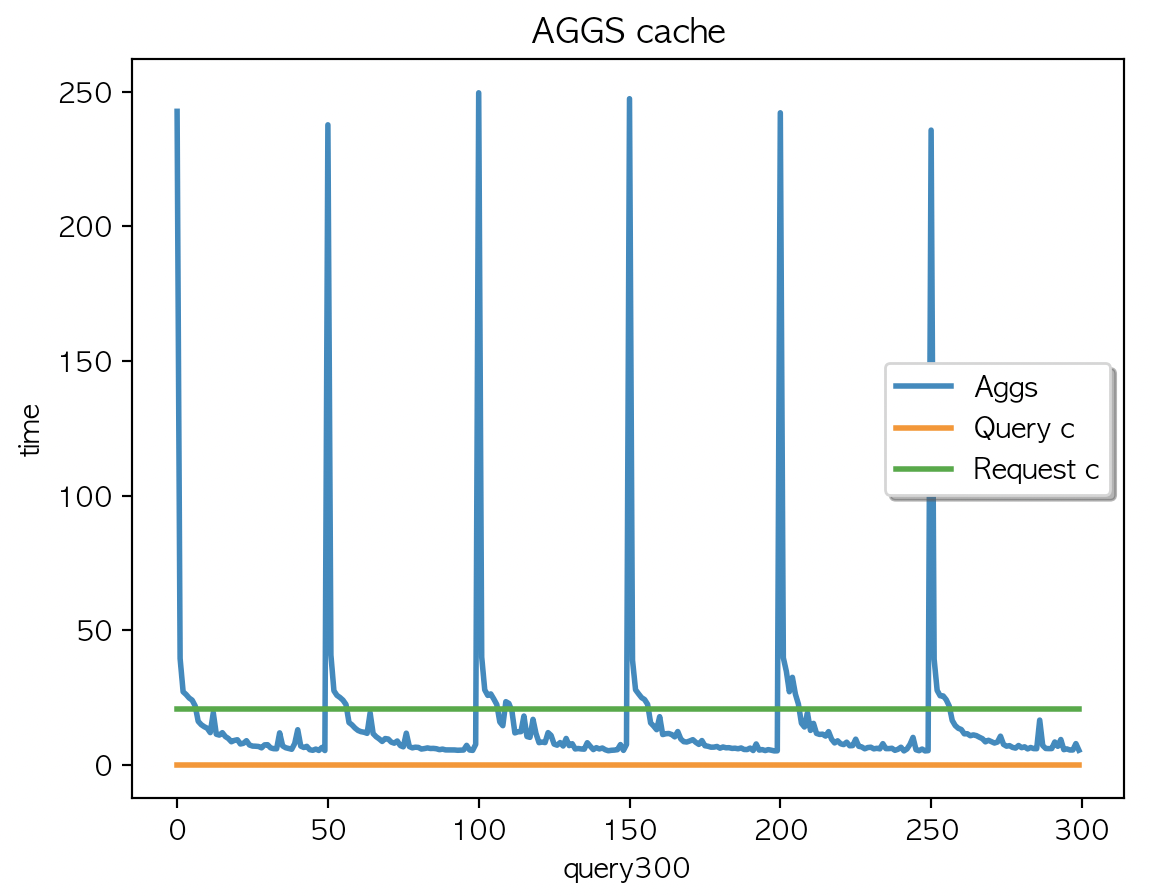
} |
 |
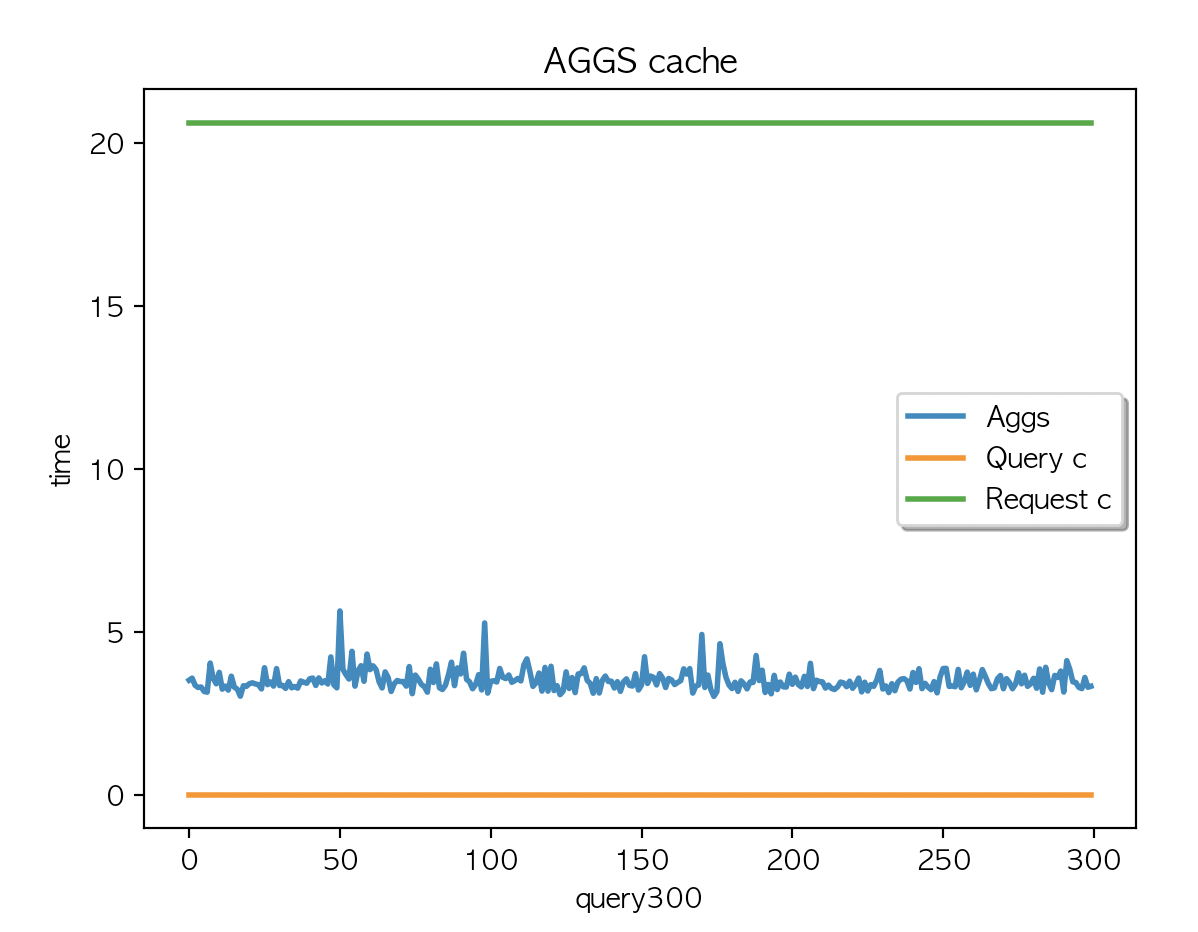 |
| AGGS 평균 : 3.58 | AGGS 평균 : 3.54 | AGGS 평균 : 3.51 |
캐싱은 되지 않았고 (캐시 사이즈 변경 없음) Aggs 속도는 50개 키워드 X 6회 반복 간헐적으로 응답시간이 튀기는 하나. ms 단위의 차이라서 크게 의미는 없어보임.
Case 3.
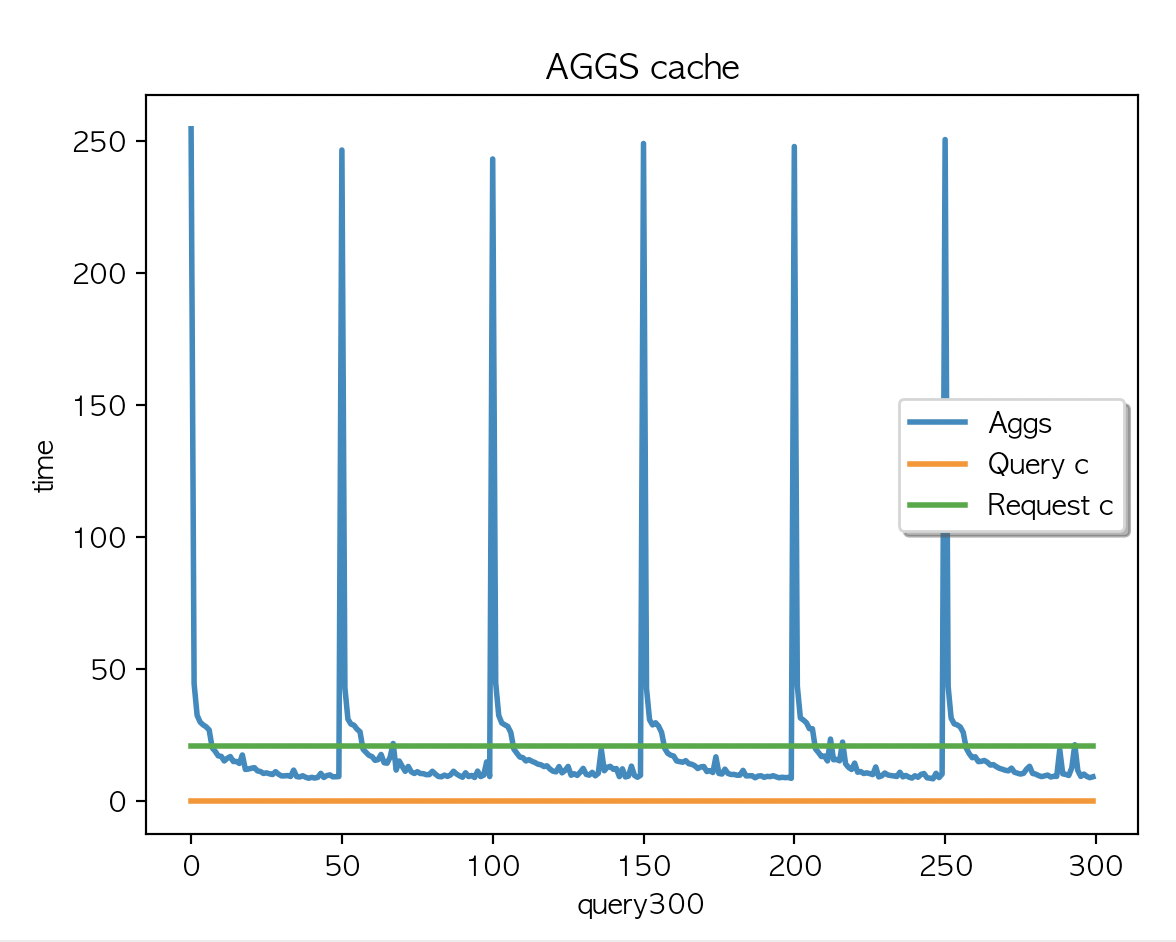
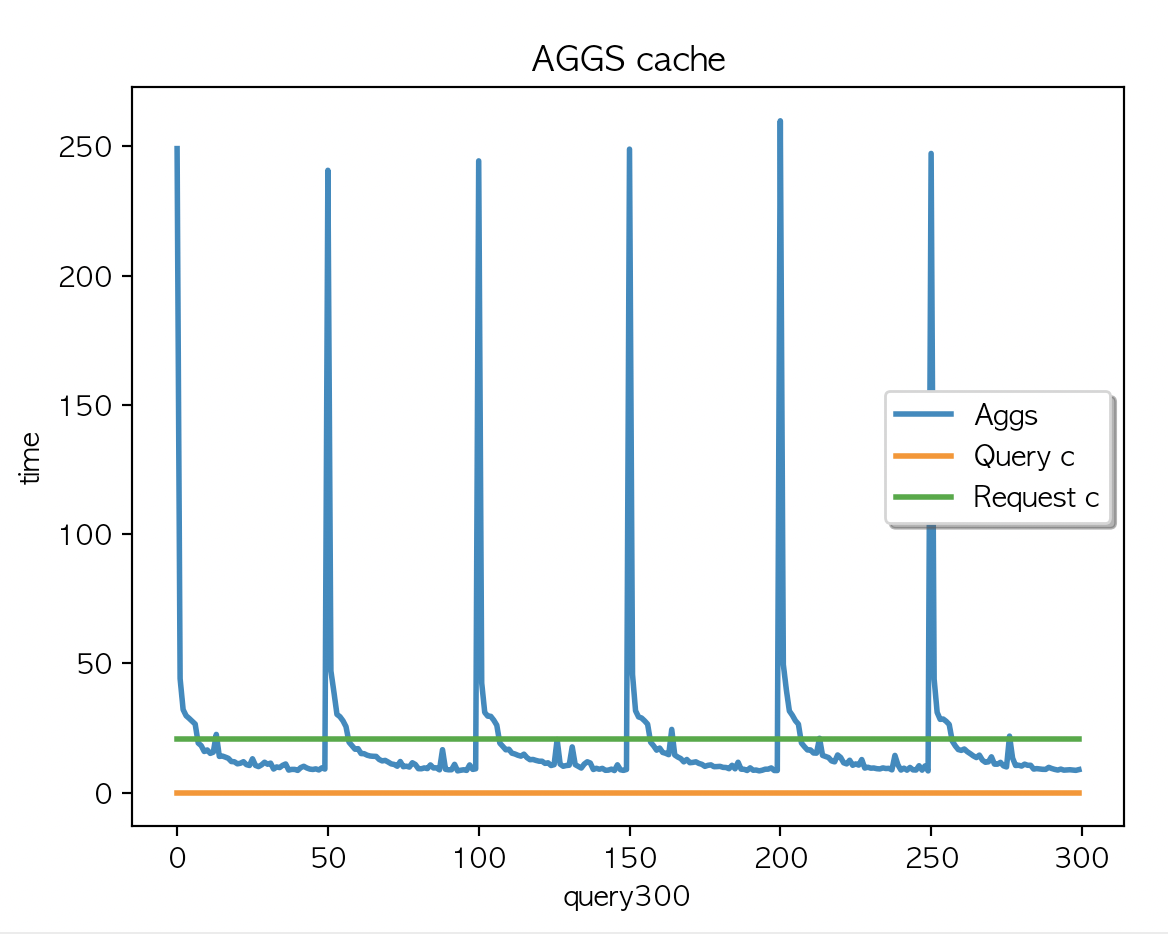
케시 지우고
multi_match + aggs 2개 필드 조회 X 300 키워드 + multi_match X 300 키워드
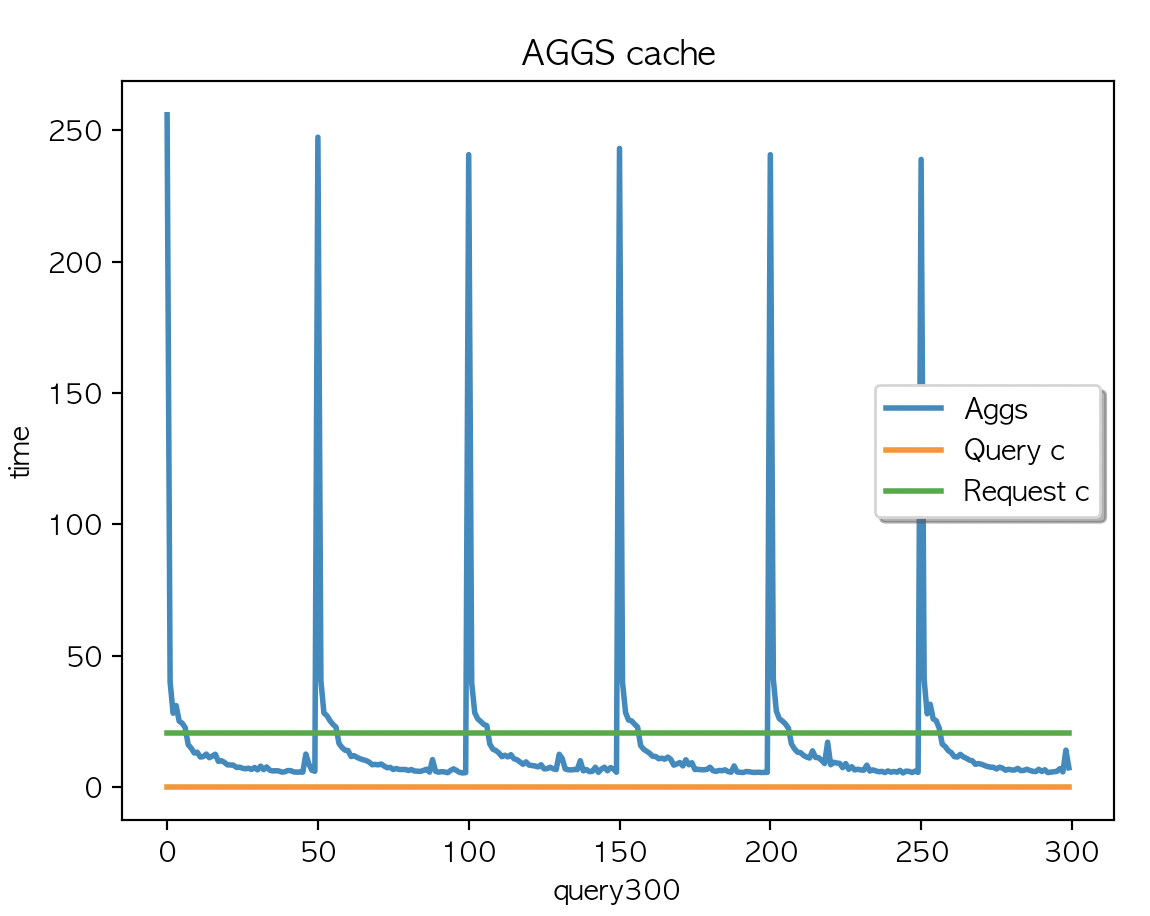
 |
 |
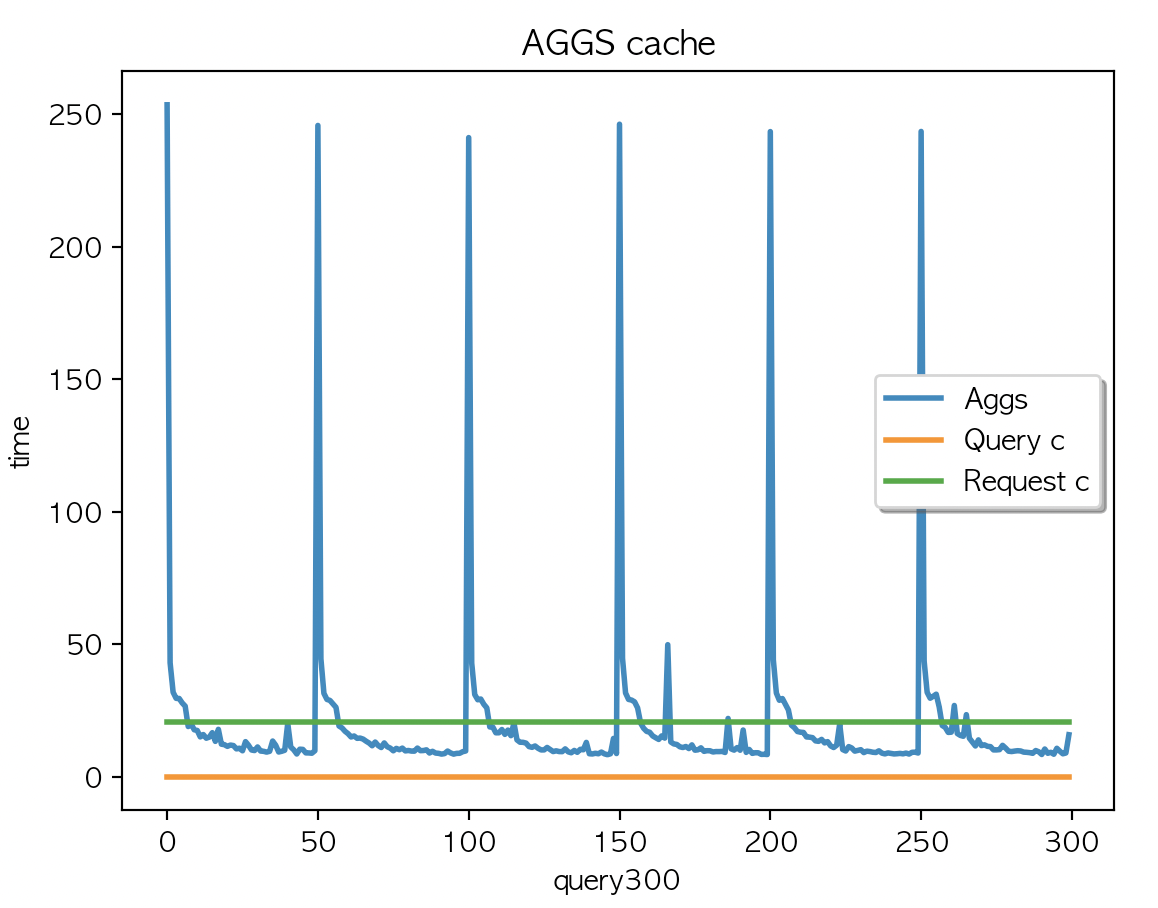 |
| AGGS 평균 : 19.06 | AGGS 평균 : 19.01 | AGGS 평균 : 19.04 |
캐싱은 되지 않았고 (캐시 사이즈 변경 없음) multi_match + aggs 2개 필드 조회 X 300 키워드 + multi_match X 300 키워드를 두번 실행한 결과값과 동일
- 이렇게 두번 실행한 이유는 aggs 결과를 먼저 캐싱해서 만들고 multi_match 쿼리를 실행 했을때 결과를 비교하기 위함
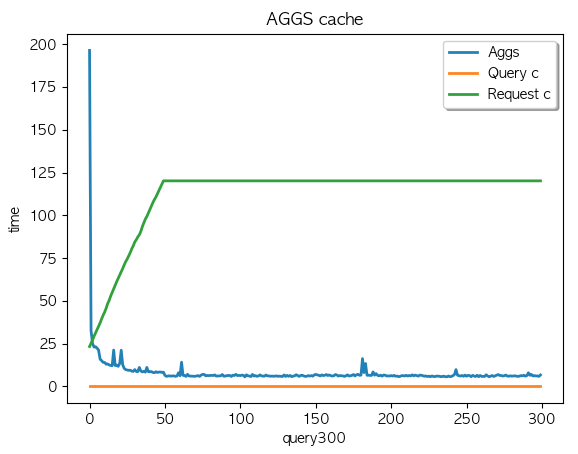
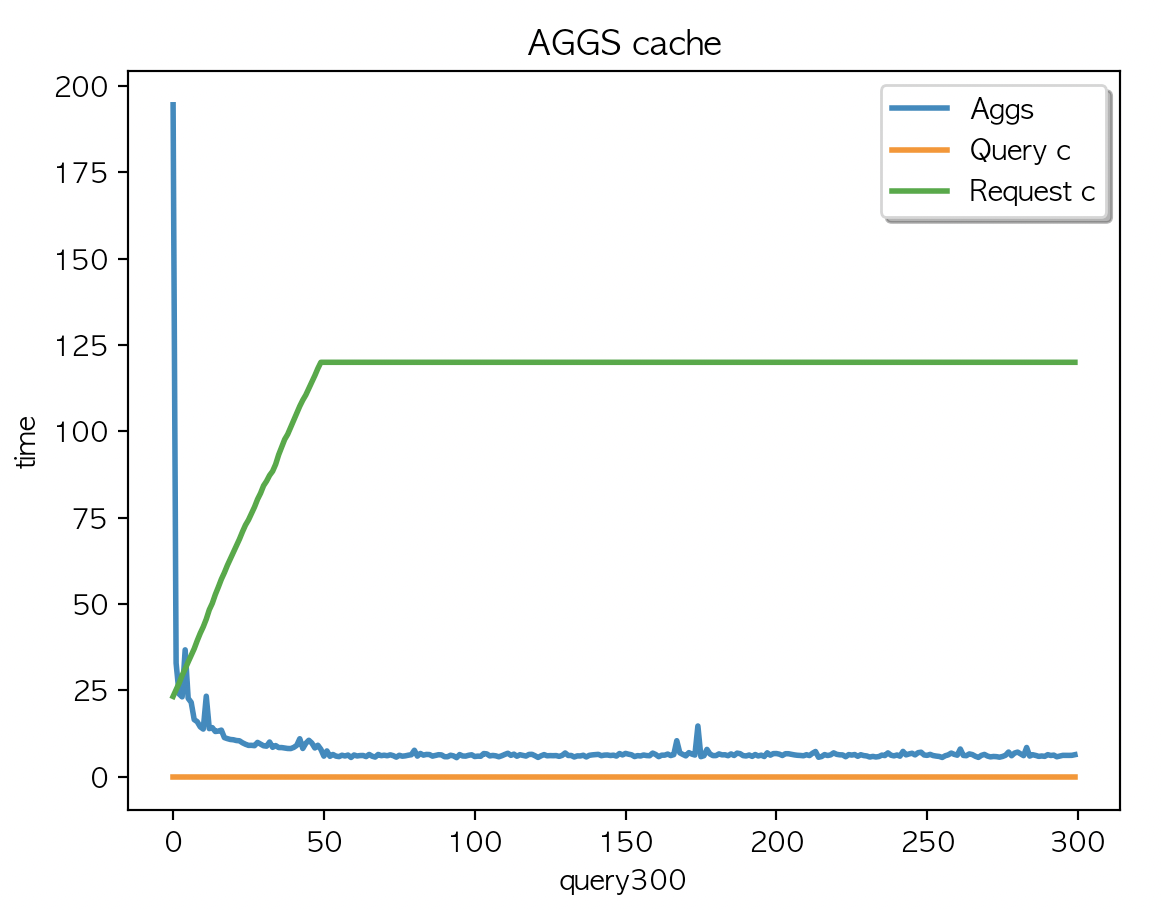
Case4.
케시 지우고
multi_match + aggs 2개 필드 조회 (캐시생성) X 300 키워드 + multi_match X 300 키워드
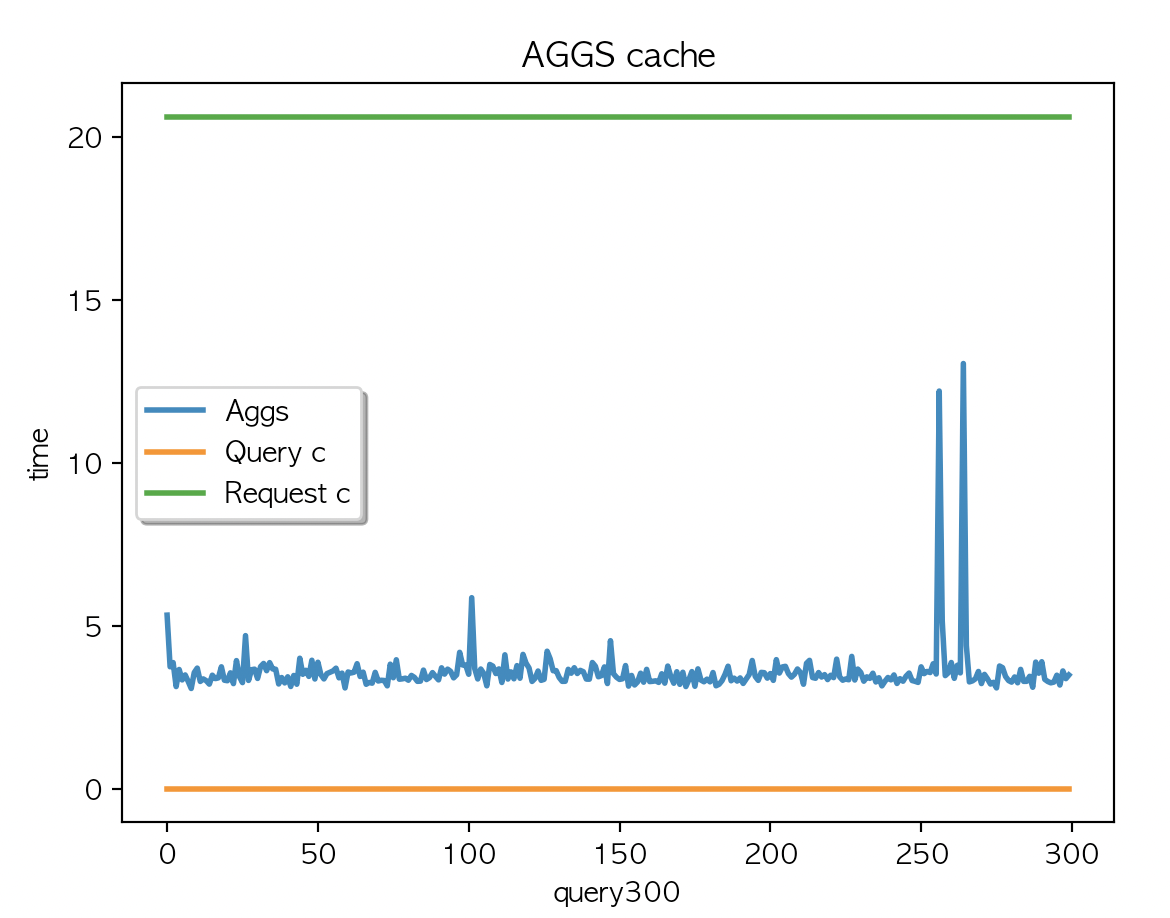
 |
 |
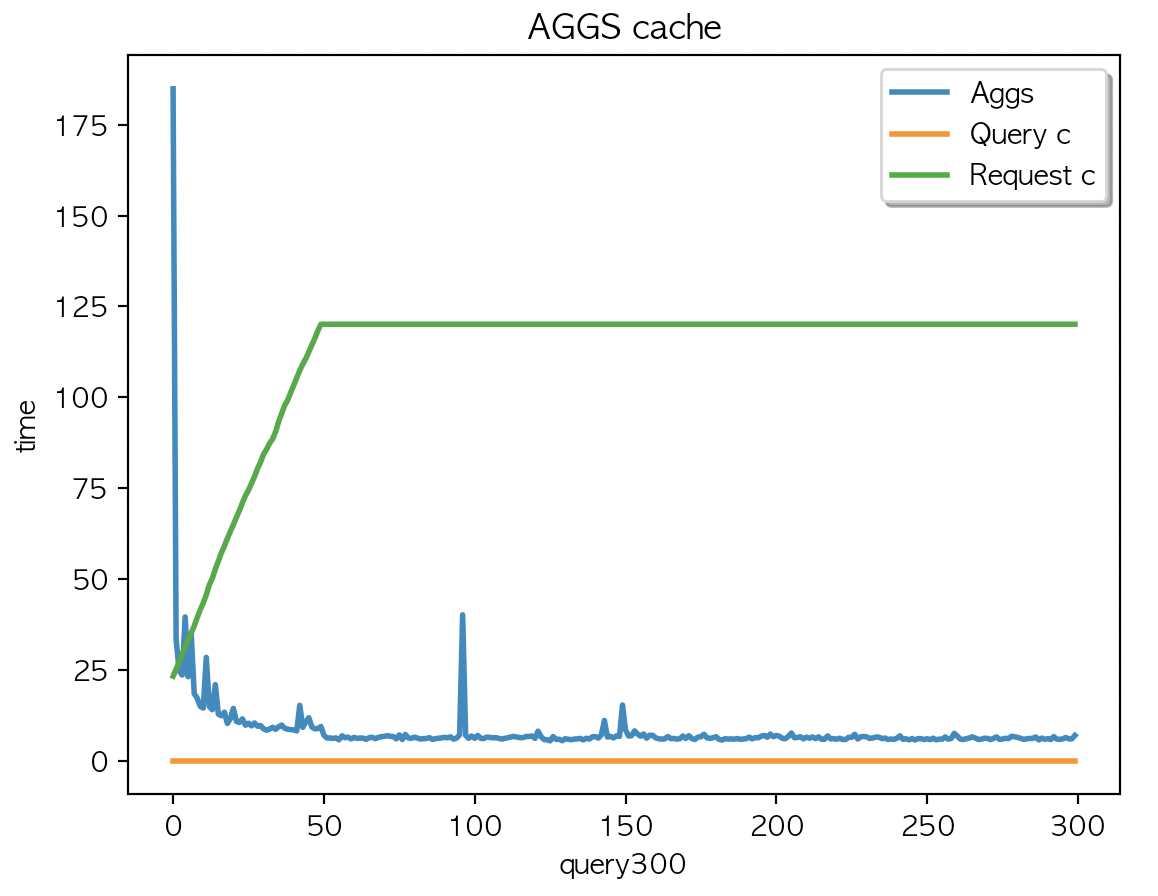 |
| AGGS 평균 : 8.03 | AGGS 평균 : 8.01 | AGGS 평균 : 8.32 |
1회부터 50회 까지의 집계결과가 캐싱되었고 데이터 조회가 디스크레벨을 조회하기전에 캐싱된 데이터에서 처리하고 있어 응답시간 감소 후 유지
캐싱데이터는 JVM heap 에 할당된 나머지 인스턴스의 메모리를 사용한다.
작업환경
로컬 경로 : /Users/doo/project/tf-embeddings/location/cache_test
가상환경 : conda activate doo
실행파일 : cache_aggs.py
# -*- coding: utf-8 -*-
import time
import matplotlib.pyplot as plt
from elasticsearch import Elasticsearch
import numpy as np
##### SEARCHING #####
def run_query_loop():
time_a = []
query_c = []
request_c = []
with open(COUNTRY_FILE) as data_file:
for line in data_file:
line = line.strip()
time_a.append(query_a(line))
query_cache, request_cache = cache_monitoring()
query_c.append(query_cache)
request_c.append(request_cache)
print("AGGS 평균 : " + str(round(np.mean(time_a), 2)))
t = range(0, len(time_a))
plt.rcParams['font.family'] = 'AppleGothic'
fig, ax = plt.subplots()
ax.set_title('AGGS cache')
line1, = ax.plot(t, time_a, lw=2, label='Aggs')
line2, = ax.plot(t, query_c, lw=2, label='Query c')
line3, = ax.plot(t, request_c, lw=2, label='Request c')
leg = ax.legend(fancybox=True, shadow=True)
ax.set_ylabel('time')
ax.set_xlabel('query' + str(len(time_a)))
lines = [line1, line2, line3]
lined = {}
for legline, origline in zip(leg.get_lines(), lines):
legline.set_picker(True) # Enable picking on the legend line.
lined[legline] = origline
def on_pick(event):
legline = event.artist
origline = lined[legline]
visible = not origline.get_visible()
origline.set_visible(visible)
legline.set_alpha(1.0 if visible else 0.2)
fig.canvas.draw()
fig.canvas.mpl_connect('pick_event', on_pick)
plt.show()
def query_a(keyword):
with open(AGGS_A) as index_file:
script_query = index_file.read().strip()
script_query = script_query.replace("{keyword}", str(keyword))
search_start = time.time()
client.search(
index=INDEX_NAME_A,
body=script_query
)
with open(AGGS_B) as index_file:
script_query = index_file.read().strip()
script_query = script_query.replace("{keyword}", str(keyword))
client.search(
index=INDEX_NAME_A,
body=script_query
)
search_time = time.time() - search_start
return search_time * 1000
def cache_monitoring():
data = client.nodes.stats()
node = data["nodes"]["bpumm1NjRAiDyuAgBN6XpQ"]["indices"]
print(node["query_cache"]["memory_size_in_bytes"])
print(node["request_cache"]["memory_size_in_bytes"])
return node["query_cache"]["memory_size_in_bytes"] / 1000, node["request_cache"]["memory_size_in_bytes"] / 1000
##### MAIN SCRIPT #####
if __name__ == '__main__':
INDEX_NAME_A = "location-index"
AGGS_A = "./query/aggs_city.json"
AGGS_B = "./query/match_query.json"
COUNTRY_FILE = "./query/country.csv"
SIZE = 300
client = Elasticsearch(http_auth=('elastic', 'dlengus'))
client.indices.clear_cache()
run_query_loop()
print("Done.")
[참고]
https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-stats.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-nodes-stats.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-stats.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-clearcache.html
'Elastic > elasticsearch' 카테고리의 다른 글
| [es] Full-cluster restart and rolling restart (0) | 2024.02.04 |
|---|---|
| [es] multi_match 쿼리와 Lucene 쿼리 구조 (1) | 2023.12.23 |
| [es] file system cache 를 이용한.. (0) | 2023.09.24 |
| [es] Warm up global ordinals (0) | 2023.09.23 |
| [es] elasticsearch 성능개선 (elasticsearch cache) (0) | 2023.09.20 |


