
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- mysql
- Docker
- Analyzer
- Aggregation
- 아이온큐
- aggs
- file download
- IONQ
- dbeaver
- TSLA
- NORI
- JPA
- Elasticsearch
- api cache
- KNN
- elasticsearch cache
- Elastic
- Cache
- java crawler
- vavr
- 양자컴퓨터
- ann
- Selenium
- aqqle
- java
- Query
- 테슬라
- request cache
- API
- redis
Archives
- Today
- Total
아빠는 개발자
[es] data node cpu 안정화 본문
728x90
반응형
이게 나를 요즘 .. 힘들게 한다...

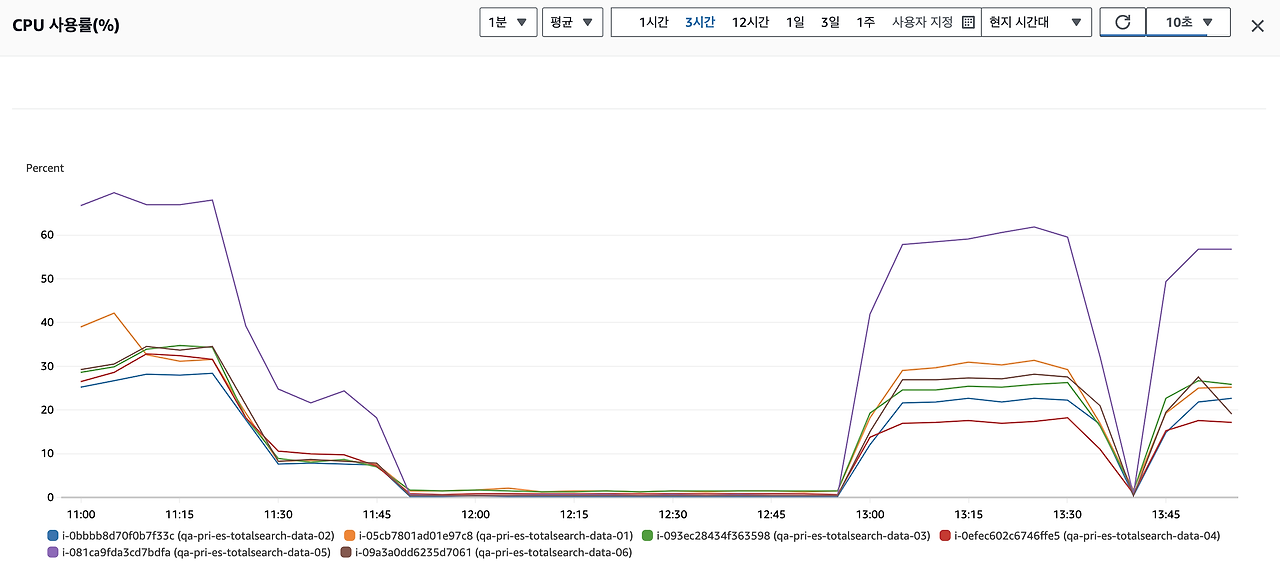
데이터 노드의 구성은 1서버 1노드 1샤드
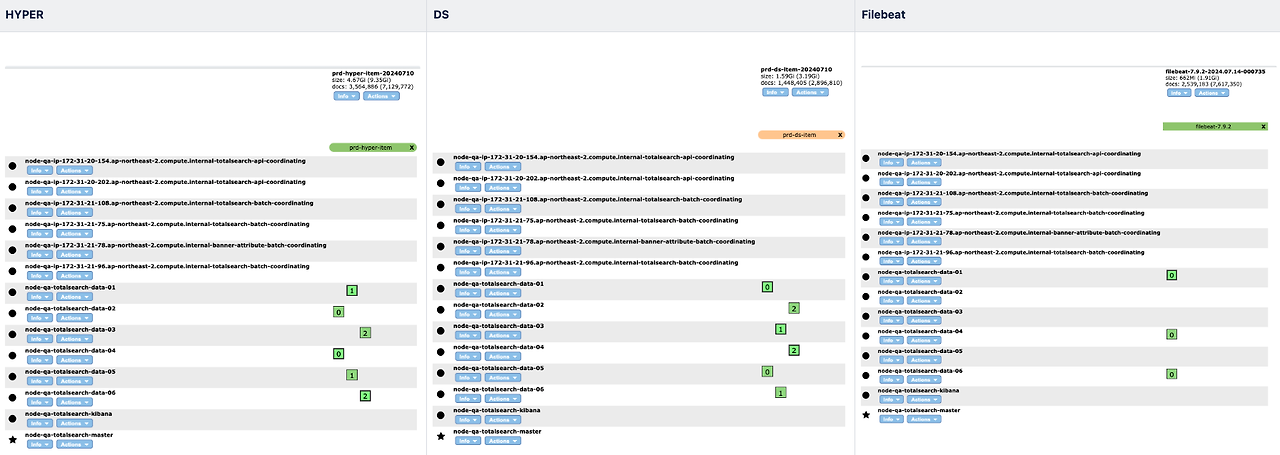
primary 3 , replica 1
어느부분이 문제를 일으키는지는 알고 있다.
제거 하고 다시 실행, 하지만 이 로직을 뺄수는 없다..
문제를 일으키는 로직은 검색결과에서 집계를 통해 필터를 만들어 내는 로직 이 로직을 파보니 query_cache 가 특정샤드에서만 상대적으로 적게 생성이 된다.
집계를 통한 필터 생성이여서 request cache 가 먹혀야 하는 구조였는데
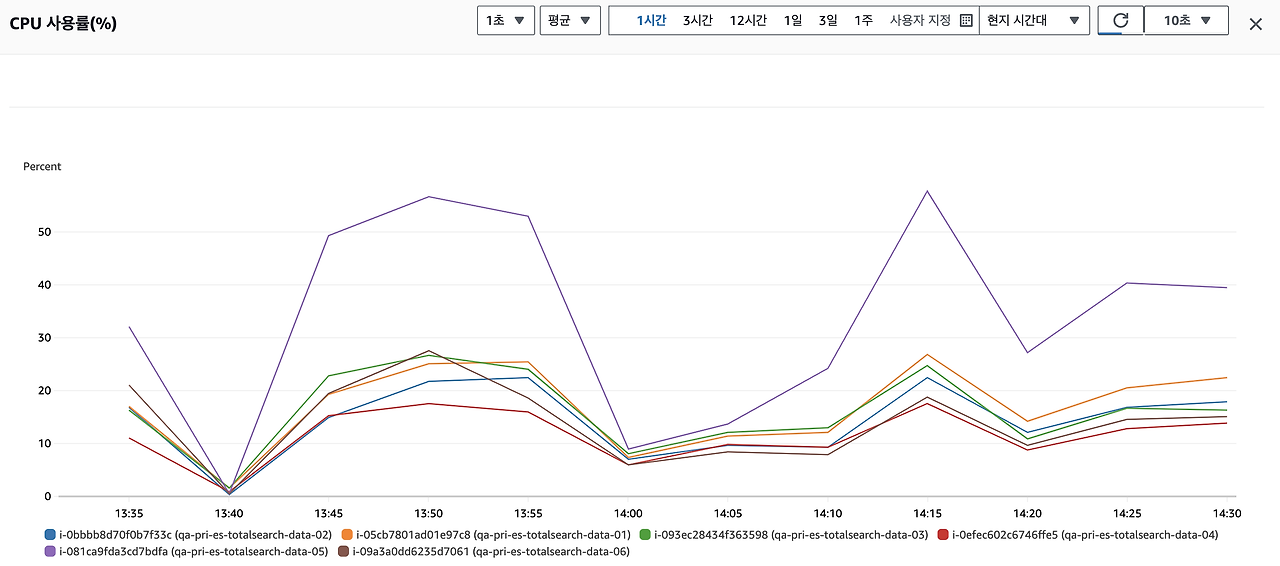
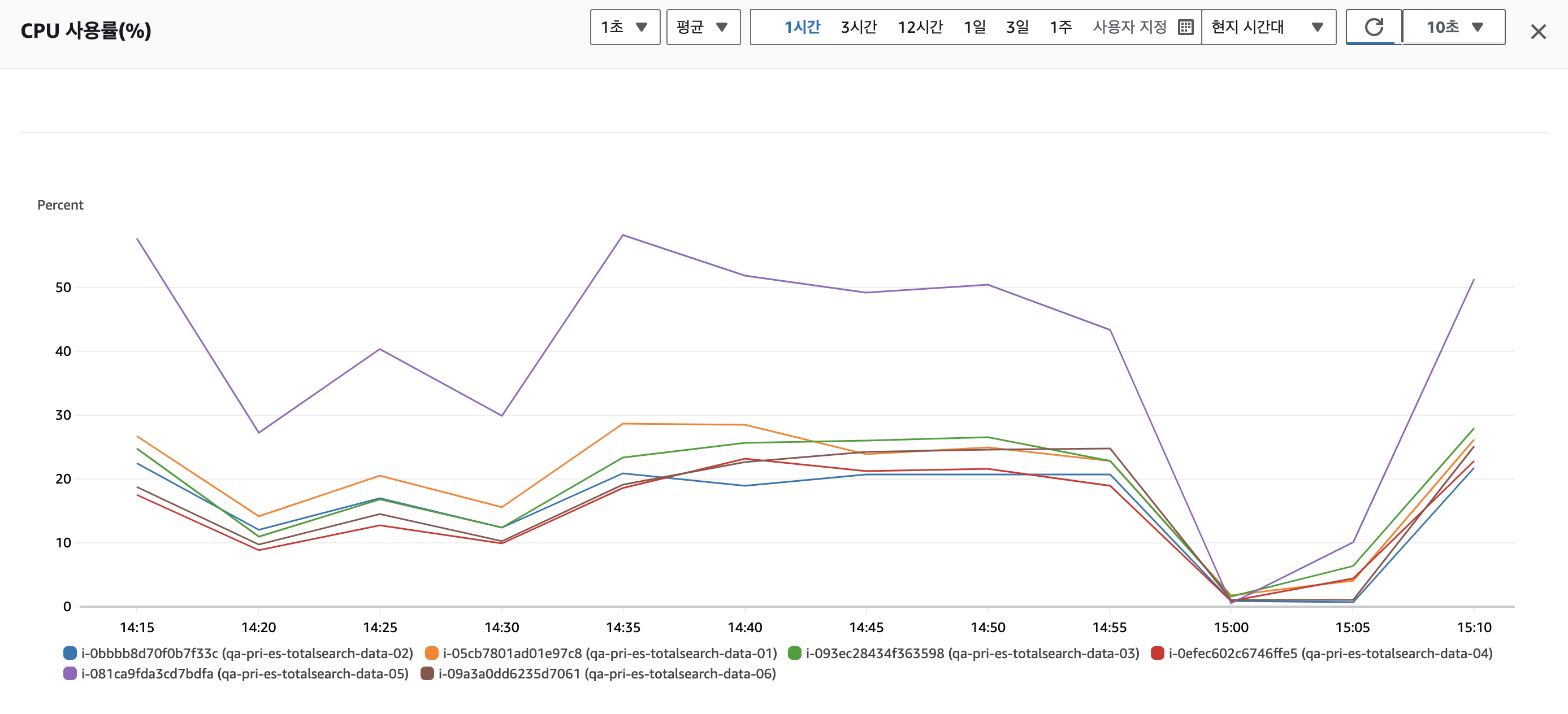
아무튼 마지막 구간에서 엄청나게 안정적인 흐름을 보이는.. 그럼 다시 널뛰는 cpu 로 만들어 놓고
해결방법
try 1
- cpu 는 트래픽이 적을땐 저렇게 하나만 튀는 현상이 없었다. redis cache 를 사용해서 트레픽을 줄여본다.
캐시전략 Lazy Loading (Cache Aside)
- 캐시 조회: 메서드가 호출되면 먼저 캐시를 조회합니다. 캐시에 해당 데이터가 있는 경우 (cache hit), 캐시된 데이터를 반환합니다.
- 캐시 미스: 캐시에 해당 데이터가 없는 경우 (cache miss), 실제 메서드를 실행하여 데이터를 가져옵니다.
- 캐시 저장: 메서드가 반환한 데이터를 캐시에 저장합니다.
- 데이터 반환: 메서드가 반환한 데이터를 클라이언트에 반환합니다.

키가 잘 생성되고 있다.
7만개를 300 개씩 조회 하고 있고 expire time 을 5분으로 가져갔을때 약 3천개의 키가 생성된다.
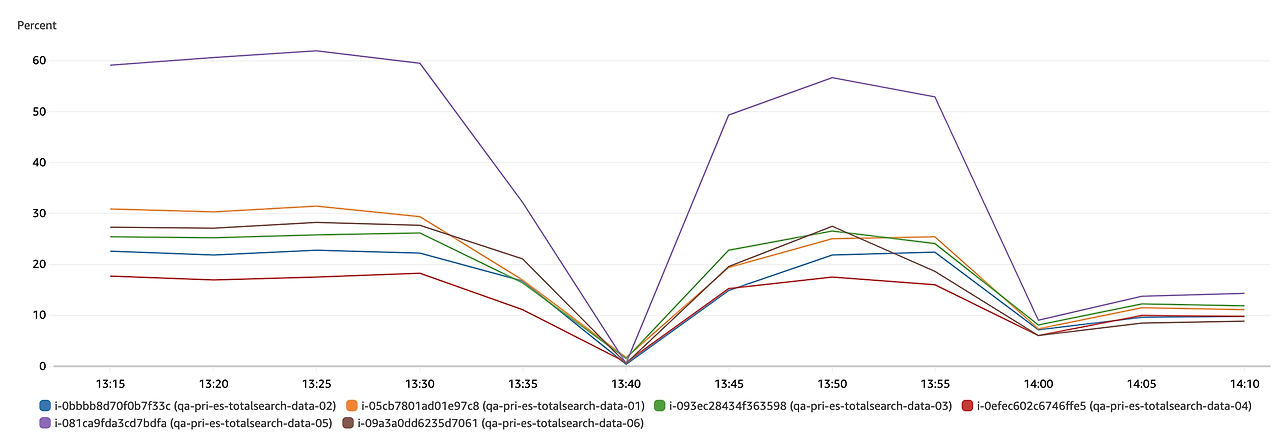
덜 튀긴 하지만 튀긴 튄다.
50% -> 40% 로 줄긴했는데 이건 레디스로 앞에서 방어를 해주니 당연한 결과이다.
try 2
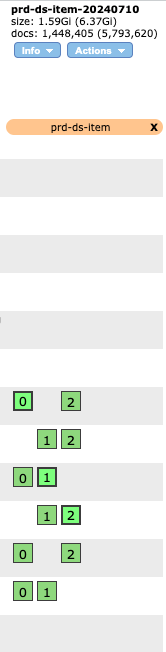
shard 재구성
1서버 2shard 원래 이걸로 됐어야 한다. 근데 테스트 결과가 원하는 결과가 안나와서 삽질을 돌도 돌고 돌아..
여기까지 왔다.
728x90
반응형
'Elastic > elasticsearch' 카테고리의 다른 글
| [es] Shard 구성 변경과 Data node (0) | 2024.08.18 |
|---|---|
| [es] 샤드 구성 변경 테스트 (0) | 2024.08.11 |
| [es] Elasticsearch data node 의 shard 정보 (0) | 2024.08.01 |
| [es] data node cpu 튀는 현상 (0) | 2024.08.01 |
| [es] Shard 와 검색 성능 - 이론편 (0) | 2024.07.28 |
'Elastic/elasticsearch' Related Articles
more



