
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- aqqle
- ann
- 테슬라
- Docker
- Elasticsearch
- api cache
- file download
- Query
- NORI
- JPA
- java crawler
- Cache
- API
- KNN
- request cache
- mysql
- elasticsearch cache
- Elastic
- Aggregation
- redis
- 양자컴퓨터
- 아이온큐
- IONQ
- vavr
- TSLA
- aggs
- dbeaver
- java
- Selenium
- Analyzer
Archives
- Today
- Total
아빠는 개발자
[es] aggregation - Pipeline Aggregations 본문
728x90
반응형
Elasticsearch aggregation 을 테스트 해보려고 한다. 그중에서도 Pipeline Aggregations
우선 내 신상 ES 로 이동
/Users/doo/docker/es8.8.1

실행해보자
(base) ➜ es8.8.1 docker compose up -d --build
docker ps -a
우선 키바나를 접속해보자
http://localhost:5601/app/home#/
오케이
인덱스는 언제더라.. 어젠가 그젠가 만들어 놓은 인덱스
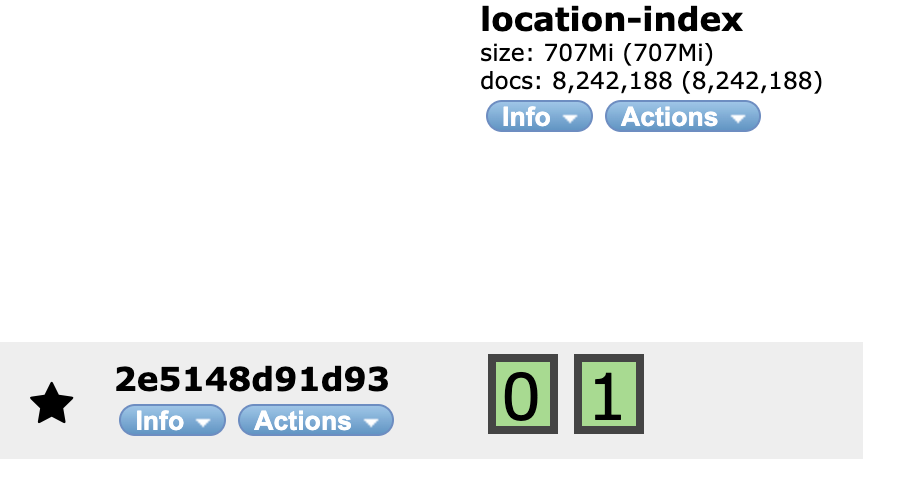
820만건의 location 정보
mapping 구조
얼레 timestamp 가 비어있네
ingest pipeline 을 만들어서 timestamp 를 찍어보잣
https://ldh-6019.tistory.com/403
[es8] Elasticsearch Timestamp Pipeline
IP 와 location 정보를 색인하는데 .. 의미는 없지만 timestamp 를 찍어 보고 싶었다. _timestamp Elasticsearch 초기 _timestamp에는 인덱스에 매핑 필드를 사용할 수 있었습니다. 이 기능은 버전 2.0부터 더 이상
ldh-6019.tistory.com
PUT /_ingest/pipeline/timestamp
{
"description": "Creates a timestamp when a document is initially indexed",
"processors": [
{
"set": {
"field": "_source.timestamp",
"value": "{{_ingest.timestamp}}"
}
}
]
}bulk class 에 timestamp pipeline 추가
bulk(client, requests, pipeline='timestamp')
색인 실행
조았으.. timestamp

timestamp
다시 aggregation 해보자 sum 을 해줄 number type 의 필드가 없어 다시 색인 ㅠㅠ

num 필드에 10000까지의 랜덤 스코어 색인
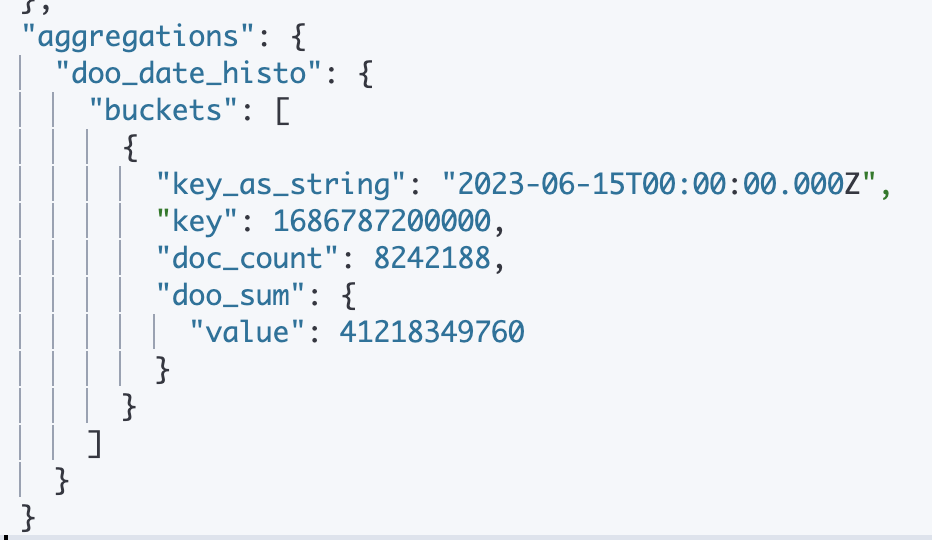
날짜별로 더 했더니
GET location-index/_search
{
"size": 0,
"aggs": {
"doo_date_histo": {
"date_histogram": {
"field": "timestamp",
"calendar_interval": "day"
},
"aggs": {
"doo_sum": {
"sum": { "field": "num" }
},
"the_deriv": {
"derivative": { "buckets_path": "doo_sum" }
}
}
}
}
}
결과
728x90
반응형
'Elastic > elasticsearch' 카테고리의 다른 글
| [es] Elasticsearch multi node cluster docker compose (0) | 2023.09.02 |
|---|---|
| [es] scripts, caching, and search speed (1) | 2023.08.31 |
| [es] script query (2) | 2023.08.31 |
| [es] HighLevelClient, LowLevelClient (1) | 2023.08.27 |
| [es] nori analyzer test (0) | 2023.08.27 |
'Elastic/elasticsearch' Related Articles
more


