
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- elasticsearch cache
- 테슬라
- JPA
- Cache
- aqqle
- Query
- file download
- IONQ
- API
- mysql
- Elasticsearch
- Elastic
- redis
- 아이온큐
- request cache
- Aggregation
- aggs
- vavr
- NORI
- java
- java crawler
- Analyzer
- Docker
- Selenium
- KNN
- 양자컴퓨터
- TSLA
- api cache
- dbeaver
- ann
Archives
- Today
- Total
아빠는 개발자
[es] nested 구조에서 aggregation 하기 - 성능테스트 본문
728x90
반응형
nested 와 object 구조에서 aggregation 테스트를 해보자
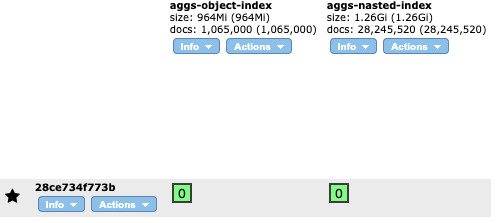
동일한 데이터를 색인하는데 nested 구조에서 index의 크기가 증가하고 docs 가 늘어난다.
100만개 색인.. 목표는 1000 만개였으나 데이터를 랜덤 숫자로 생성하는데도 시간이 꽤 오래 걸렸다..
그래서 중간에 멈추고 리프레시 실행
인덱스 생성 쿼리
nested index
{
"settings": {
"number_of_shards": {SHARD_SIZE},
"number_of_replicas": 0
},
"mappings": {
"dynamic": "true",
"_source": {
"enabled": "true"
},
"properties": {
"name": {
"type": "keyword"
},
"promos": {
"type": "nested",
"properties": {
"promo": {
"type": "keyword"
},
"theme": {
"type": "keyword"
}
}
},
"timestamp": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
}
}
}
}
object index
{
"settings": {
"number_of_shards": {SHARD_SIZE},
"number_of_replicas": 0
},
"mappings": {
"dynamic": "true",
"_source": {
"enabled": "true"
},
"properties": {
"name": {
"type": "keyword"
},
"promos": {
"properties": {
"promo": {
"type": "keyword"
},
"theme": {
"type": "keyword"
}
}
},
"timestamp": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
}
}
}
}
위 두개의 인덱스를 생성하고
인덱스 생성 / 색인
# -*- coding: utf-8 -*-
import random
import time
import json
import csv
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
import matplotlib.pyplot as plt
import kss, numpy
##### INDEXING #####
def index_create(INDEX, INDEX_FILE):
print("Creating the '" + INDEX + "' index.")
client.indices.delete(index=INDEX, ignore=[404])
with open(INDEX_FILE) as index_file:
source = index_file.read().strip().replace('{SHARD_SIZE}', SHARD_SIZE)
client.indices.create(index=INDEX, body=source)
def indexing():
datas = []
line_count = 0
for i in range(0, DATA_LOWS):
promos = []
name = "상품-" + str(i)
for j in range(0, random.randint(1,50)):
promo = random.randint(1000, 2000)
print(promo)
theme = []
for k in range (0,random.randint(1,6)):
theme.append(random.randint(10000, 20000))
promos.append({'promo': promo, 'theme': theme})
line_count += 1
row_dict = {'name': name, 'promos': promos}
datas.append(row_dict)
if line_count % BATCH_SIZE == 0:
index_batch(NESTED_INDEX, datas)
index_batch(OBJECT_INDEX, datas)
datas = []
if len (datas) > 0:
index_batch(NESTED_INDEX, datas)
index_batch(OBJECT_INDEX, datas)
datas = []
refresh_index(NESTED_INDEX)
refresh_index(OBJECT_INDEX)
def refresh_index(INDEX):
client.indices.refresh(index=INDEX)
print("Done indexing.")
def index_batch(INDEX, docs):
requests = []
for i, doc in enumerate(docs):
request = doc
request["_op_type"] = "index"
request["_index"] = INDEX
requests.append(request)
bulk_start = time.time()
bulk(client, requests, pipeline='timestamp')
return (time.time() - bulk_start)
##### MAIN SCRIPT #####
if __name__ == '__main__':
client = Elasticsearch(http_auth=('elastic', 'dlengus'))
INDEX_NAME = "aggs-"
SHARD_SIZE = '1'
NESTED_INDEX = INDEX_NAME + "nasted-index"
NESTED_INDEX_FILE = "../sql/nested_aggs_index.json"
OBJECT_INDEX = INDEX_NAME + "object-index"
OBJECT_INDEX_FILE = "../sql/object_aggs_index.json"
DATA_LOWS = 10000000
BATCH_SIZE = 5000
index_create(NESTED_INDEX, NESTED_INDEX_FILE)
index_create(OBJECT_INDEX, OBJECT_INDEX_FILE)
indexing()
print("Done.")
상품과 promos 의 배열구조로 데이터 색인
색인된 데이터를 확인해보면 대충 이런식으로 색인되어 있다.
요약하면 하나의 상품은 다수의 프로모션에 등록될 수 있고 프로모션은 다수의 테마를 가지고 있다.

검색쿼리
nested search query - promotion 번호로 필터링 후 aggregation 한다.
{
"size": 0,
"query": {
"nested": {
"path": "promos",
"query": {
"bool": {
"filter": [
{
"term": {
"promos.promo": "{promo_no}"
}
}
]
}
}
}
},
"aggs": {
"nested_promos": {
"nested": {
"path": "promos"
},
"aggs": {
"PROMO": {
"terms": {
"field": "promos.promo"
},
"aggs": {
"THEME": {
"terms": {
"field": "promos.theme"
}
}
}
}
}
}
}
}
nested 와 동일한 구조 search query - promotion 번호로 필터링 후 aggregation 한다.
{
"size": 0,
"query": {
"bool": {
"filter": [
{
"term": {
"promos.promo": "{promo_no}"
}
}
]
}
},
"aggs": {
"PROMO": {
"terms": {
"field": "promos.promo"
},
"aggs": {
"THEME": {
"terms": {
"field": "promos.theme"
}
}
}
}
}
}
검색실행 및 결과 수집
# -*- coding: utf-8 -*-
import time
import matplotlib.pyplot as plt
from elasticsearch import Elasticsearch
import numpy as np
##### SEARCHING #####
def run_query_loop():
time_a = []
query_c = []
request_c = []
with open(PROMO_FILE) as data_file:
for line in data_file:
line = line.strip()
# time_a.append(query_nested(line))
time_a.append(query_object(line))
query_cache, request_cache = cache_monitoring()
query_c.append(query_cache)
request_c.append(request_cache)
print("AGGS 평균 : " + str(round(np.mean(time_a), 2)))
t = range(0, len(time_a))
plt.rcParams['font.family'] = 'AppleGothic'
fig, ax = plt.subplots()
ax.set_title('AGGS cache')
line1, = ax.plot(t, time_a, lw=1, label='Aggs')
line2, = ax.plot(t, query_c, lw=1, label='Query c')
line3, = ax.plot(t, request_c, lw=1, label='Request c')
leg = ax.legend(fancybox=True, shadow=True)
ax.set_ylabel('time')
ax.set_xlabel('query' + str(len(time_a)))
lines = [line1, line2, line3]
lined = {}
for legline, origline in zip(leg.get_lines(), lines):
legline.set_picker(True) # Enable picking on the legend line.
lined[legline] = origline
def on_pick(event):
legline = event.artist
origline = lined[legline]
visible = not origline.get_visible()
origline.set_visible(visible)
legline.set_alpha(1.0 if visible else 0.2)
fig.canvas.draw()
fig.canvas.mpl_connect('pick_event', on_pick)
plt.show()
def query_nested(keyword):
with open(AGGS_NESTED) as index_file:
script_query = index_file.read().strip()
script_query = script_query.replace("{promo_no}", str(keyword))
search_start = time.time()
response = client.search(
index=NESTED_INDEX,
body=script_query
)
search_time = time.time() - search_start
return search_time * 1000
def query_object(keyword):
with open(AGGS_OBJECT) as index_file:
script_query = index_file.read().strip()
script_query = script_query.replace("{promo_no}", str(keyword))
search_start = time.time()
response = client.search(
index=OBJECT_INDEX,
body=script_query
)
search_time = time.time() - search_start
return search_time * 1000
def cache_monitoring():
data = client.nodes.stats()
node = data["nodes"]["bpumm1NjRAiDyuAgBN6XpQ"]["indices"]
print(node["query_cache"]["memory_size_in_bytes"])
print(node["request_cache"]["memory_size_in_bytes"])
return node["query_cache"]["memory_size_in_bytes"] / 1000, node["request_cache"]["memory_size_in_bytes"] / 1000
##### MAIN SCRIPT #####
if __name__ == '__main__':
NESTED_INDEX = "aggs-nasted-index"
OBJECT_INDEX = "aggs-object-index"
AGGS_NESTED = "../query/nested_query.json"
AGGS_OBJECT = "../query/object_query.json"
PROMO_FILE = "./data/promo.txt"
SIZE = 300
client = Elasticsearch(http_auth=('elastic', 'dlengus'))
client.indices.clear_cache()
run_query_loop()
print("Done.")
object
AGGS 평균 : 999.92
첫번째 시도가 뻥 튀기 되었지만 평균적으로 900ms 이상으로 실행 되고 있다.

nested
AGGS 평균 : 184.4
이것도 첫 시도가 뻥튀기 되었고 평균 180ms 대로 실행되고 있다.

nested 구조에서 캐시 사용하면
AGGS 평균 : 3.61

보시다 시피 둘다 Request cache 를 생성하고 있고 동일한 파라미터 promo_no 로 실행되었을때 캐시를 사용하여 3ms 대로 실행되고 있다.
캐시 만세!
728x90
반응형
'Elastic > elasticsearch' 카테고리의 다른 글
| [es] elasticsearch 검색엔진 동작 (0) | 2024.07.28 |
|---|---|
| [es] 엘라스틱서치 샤드 최적화 (1) | 2024.06.29 |
| [es] nested 구조에서 aggregation 하기 (2) | 2024.04.30 |
| [es] elasticsearch index copy 를 mac 에서 (0) | 2024.04.06 |
| [es] Hot Threads API (0) | 2024.02.24 |
'Elastic/elasticsearch' Related Articles
more

