[java] API - redis cache for method TEST
메소드 별로 redis 케시를 태워서 검색 성능을 최적화 해보자

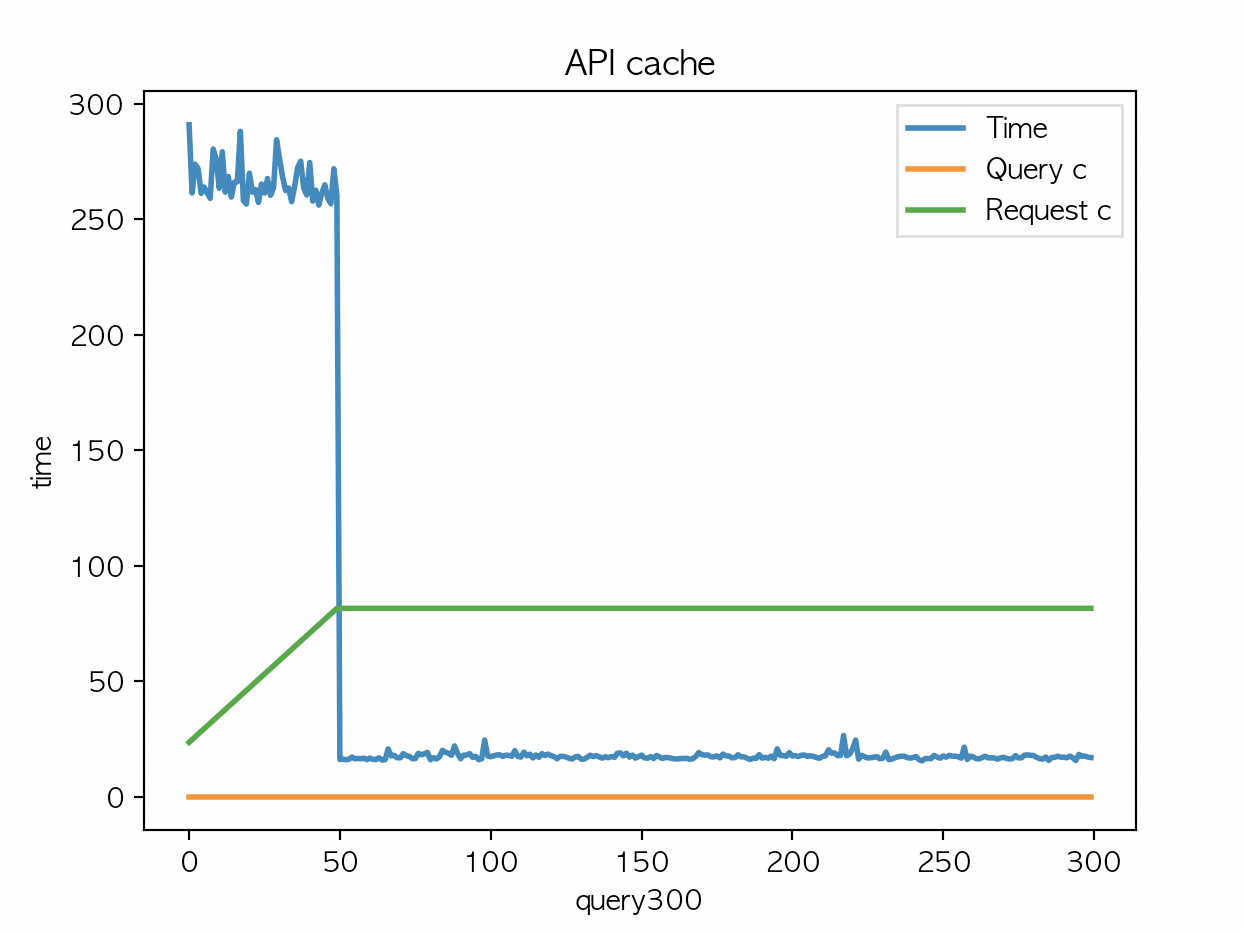
Cache Api 에서 multi_match 쿼리 1 회, multi_match 쿼리 + Aggs 3회 를 실행한다.
file system cache : 적용
redis cache : 미적용
 |
 |
 |
| API 평균 : 58.97 | API 평균 : 58.28 | API 평균 : 58.19 |
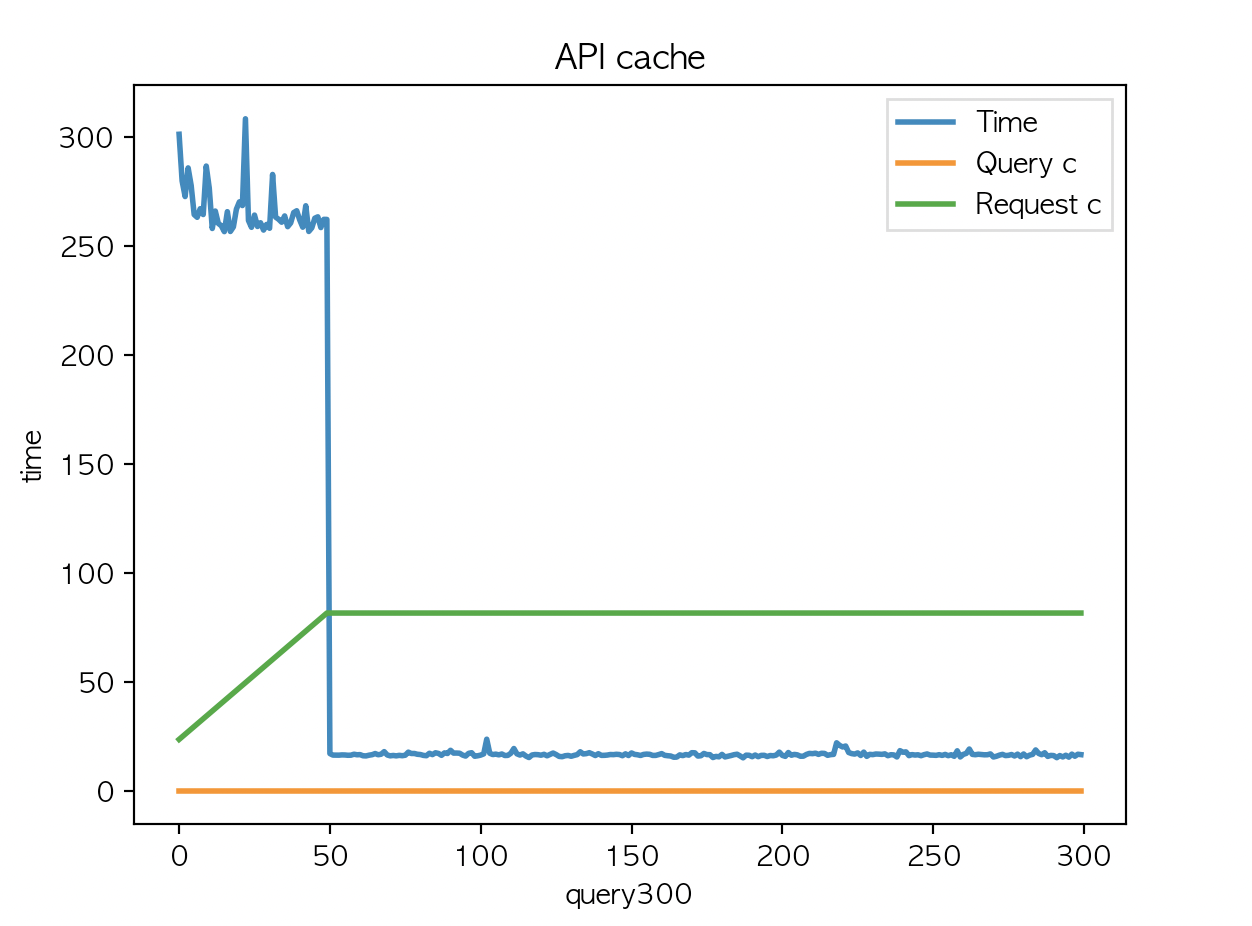
Cache Api 에서 multi_match 쿼리 1 회, multi_match 쿼리 + Aggs 3회 를 실행한다. 여기서 Aggs 처리하는 메소드에 redis cache 를 적용하고 cache key 는 country code 로 한다.
file system cache : 적용
redis cache : 적용
 |
 |
 |
| API 평균 : 61.48 | API 평균 : 13.01 | API 평균 : 12.47 |
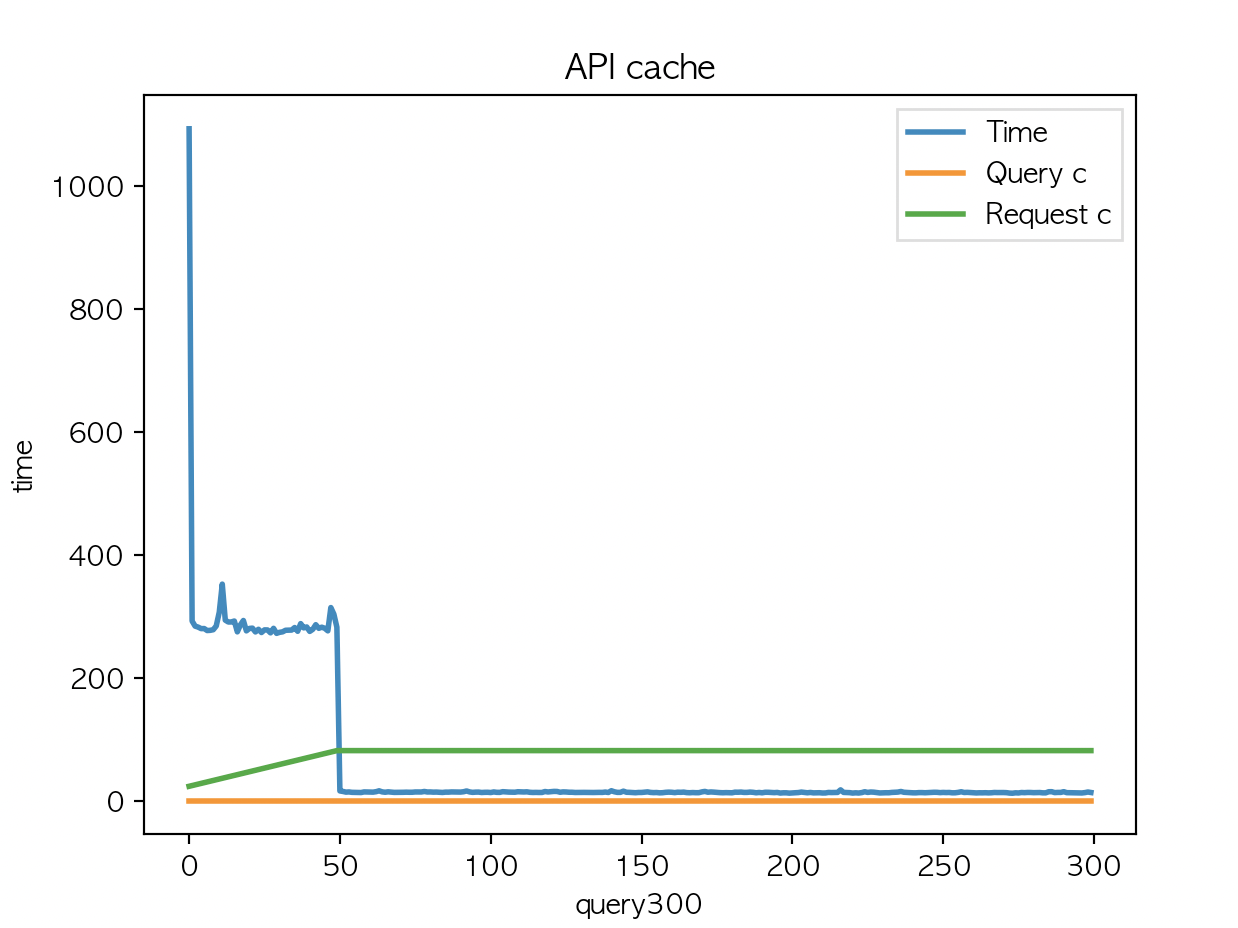
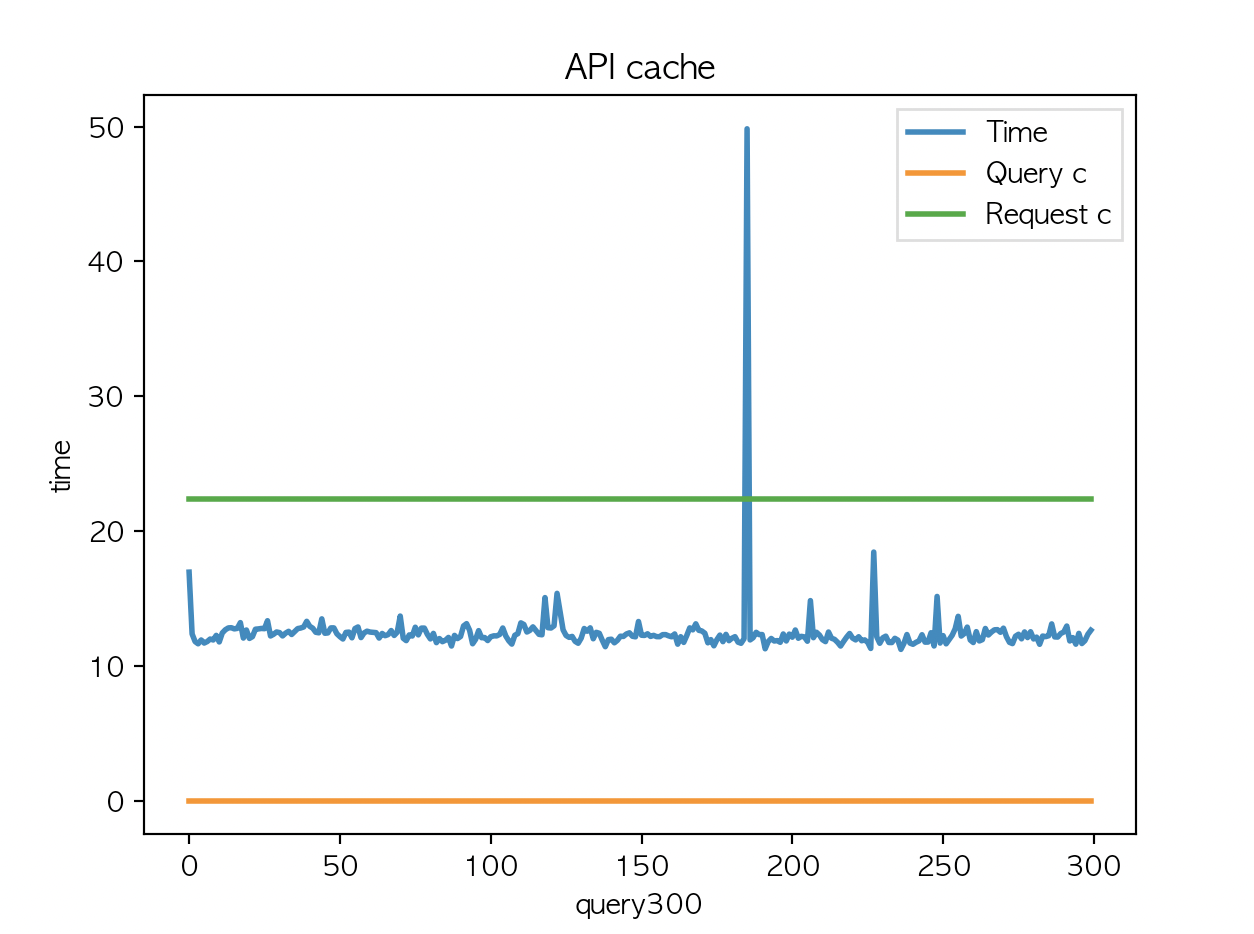
여기까진 예상했던 결과인데 캐시유효시간 반으로 줄이고 country code 카디널리티를 50에서 200 으로 해본다.
(base) ➜ query git:(main) ✗ sed '/^ *$/d' country200.csv > country200_1.csv
빈행이나 공백을 제거한 후 새 파일로 저장
(base) ➜ query git:(main) ✗ cat country200.csv | grep -v '^"doc' | sed '/^ *$/d' > country200_1.csv
"doc 로 시작하거나 빈행이나 공백을 제거한 후 새 파일로 저장
200 X 5 로 1000개 반복
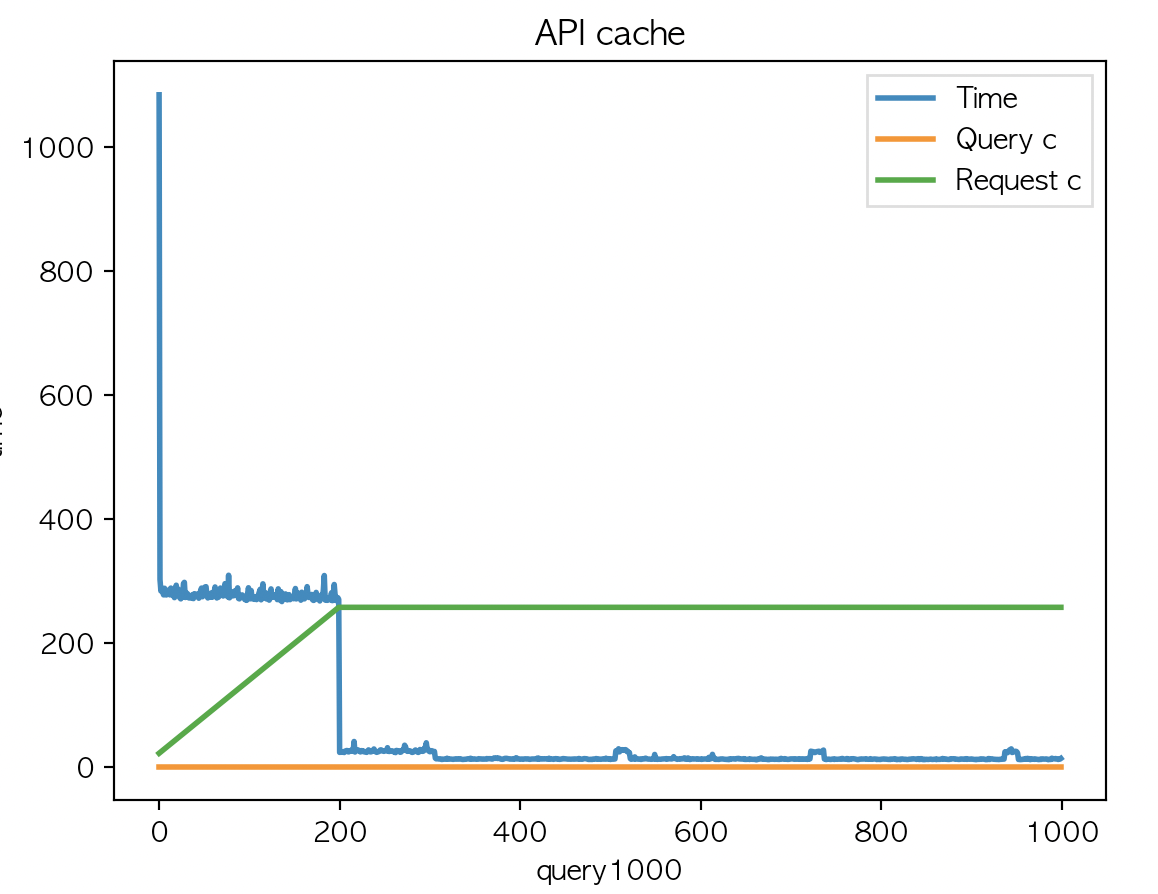 |
 |
 |
| API 평균 : 68.38 | API 평균 : 66.4 | API 평균 : 66.32 |
음..
캐시키를 어떻게 설정하는냐가.. 관건인데..
메소드별로 캐싱이 가능하다는 것을 확인했으니 운영시스템과 비슷한 구조의 프로토타입을 만들어서 테스트 해봐야겠다.